Mike Nucci
?? min read
Load Testing Conversation Analysis in Snowflake
We tried to rebuild Rippit inside Snowflake to see if Cortex could do it alone. It didn't crash at 200 users — but "it didn't crash" is a low bar.
BLOG


.png)
We tried to rebuild Rippit inside Snowflake to see if Cortex could do it alone. It didn't crash at 200 users — but "it didn't crash" is a low bar.
I really enjoy using Snowflake. I'm in it constantly. It's where our data lives, and most days it just quietly does what I need it to do.
I run finance and operations at Rippit. Part of what we do is conversation intelligence. Point us at your sales and support calls and we turn them into answers.
And Snowflake has a built-in AI service, Cortex, sitting right next to all that conversation data.
Which raises an obvious, slightly terrifying question:
Could you just… do this yourself, in Snowflake, without Rippit?
I genuinely wanted to know. Part curiosity, part self-preservation: if Snowflake can already do this on its own, Rippit's in real trouble.
So I tried to build Rippit in Snowflake, or at least the core of it, and push it until something broke.
The dream version is simple. Someone types a plain-English question — how are customers talking about us this month? which deals are slipping, and why? — and the system calls an LLM against the actual transcripts, on the fly, and hands back an answer.
All inside Snowflake. No extra infrastructure, no data leaving the building.
But before any of that, before Cortex reads a single word, I had to get the conversations into a shape so that the LLM could even analyze them.
Our conversations don't live in one tidy place. Sales calls come from Gong, support chats from Intercom. Both sync into Snowflake through Fivetran, but they land raw. And raw is a mess.
A Gong call isn't a transcript; it's hundreds of rows, one per spoken sentence, scattered across tables with speaker IDs and timestamps.
Intercom is the same idea in a different shape: each conversation is a pile of message "parts," wrapped in HTML, tagged by whether an agent, a customer, or a bot wrote them.
So before I could analyze anything, I had to do real data modeling.
That's a stack of dbt models and a daily pipeline standing between raw data and the very first question. None of it is hard, exactly, but it's hours of work and design decisions that I had to make. The LLM can't read what I hadn’t cleaned yet.
With the data finally in one clean, queryable place, I wired it up and started turning the dial: one user, then ten, then a hundred, then two hundred all asking at once.
I tracked how fast it answered, what it cost, and what fell over.
A few things surprised me.
When it felt slow, my first instinct was the lazy one: throw more hardware at it.
I 4x’d the compute. It only got 8% faster.
Here's why. The AI doesn't actually run on the computer you're paying to scale up. It runs on a separate, shared service behind the platform. Your compute just takes the order and carries the plate. The kitchen is somewhere else, and it cooks at its own pace.
A fancier waiter doesn't make the kitchen cook faster.
One answer is cheap. Reading a single transcript to answer a question costs about four cents on a premium model. Nobody's going to notice four cents.
But the questions worth asking don't read one transcript. They read all of them.
"Give me a competitive rundown across last quarter's calls" means actually reading last quarter's calls. Two hundred and fifty of them run about $11 and fifty minutes.
And it runs again, from scratch, every time someone tweaks the question or the data refreshes.
A premium model does give you a better answer: sharper, better at holding a complicated instruction. You just pay for that quality every time, across every conversation, and nothing warns you when you've wandered onto the expensive path.
We're used to AI replying in a second or two. That holds for one short question. It stops holding the moment you ask it to read a lot.
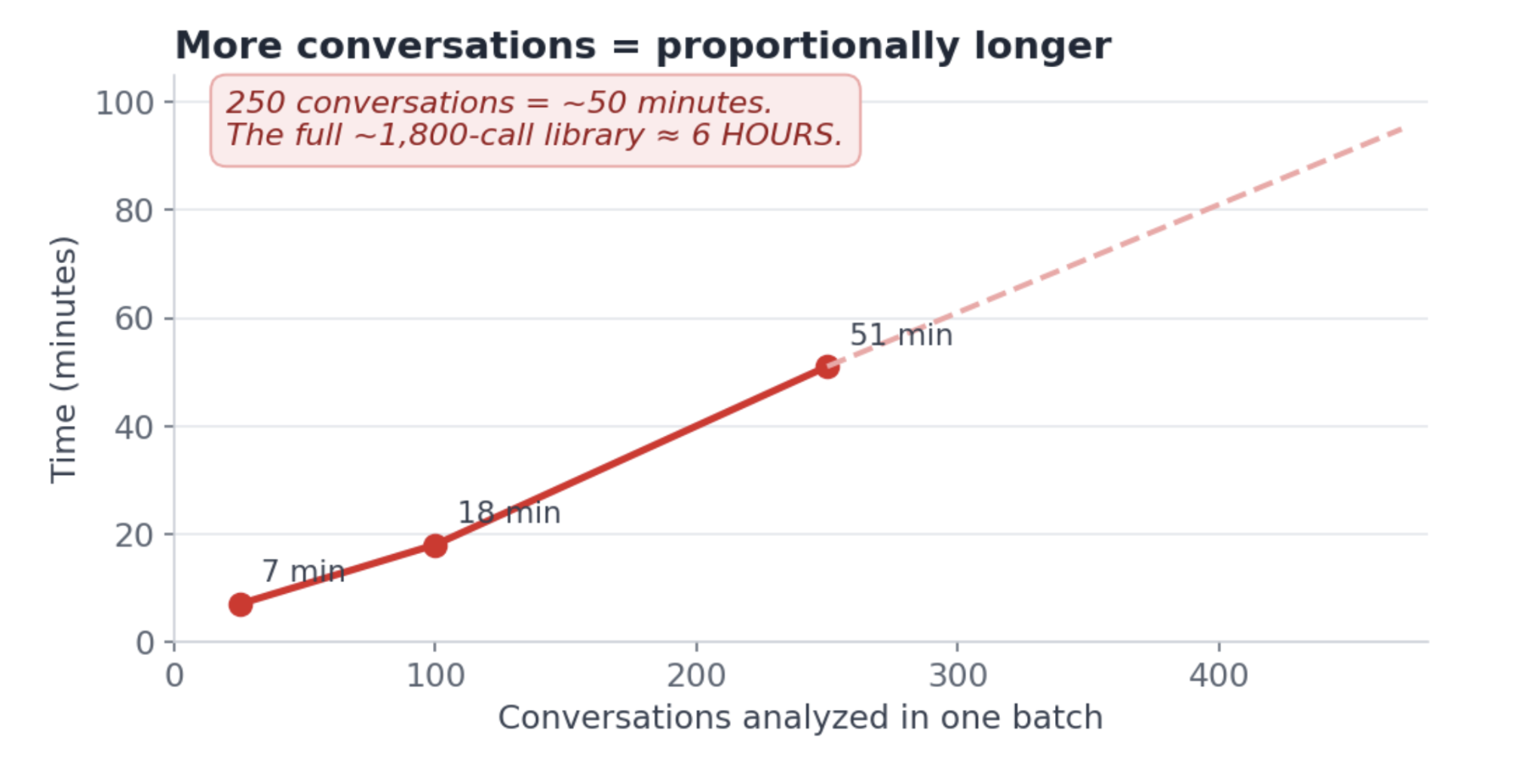
Twelve seconds per conversation. Fine on its own. But 250 conversations is nearly an hour.
The time grows in a straight line with the volume. There's no setting that makes "read everything" fast.
This was the real test I cared about. Picture a sales team on a Monday morning: dozens of reps all opening the tool and asking about their own accounts at the same time.
So I built up to it: a hundred simultaneous users, then two hundred.
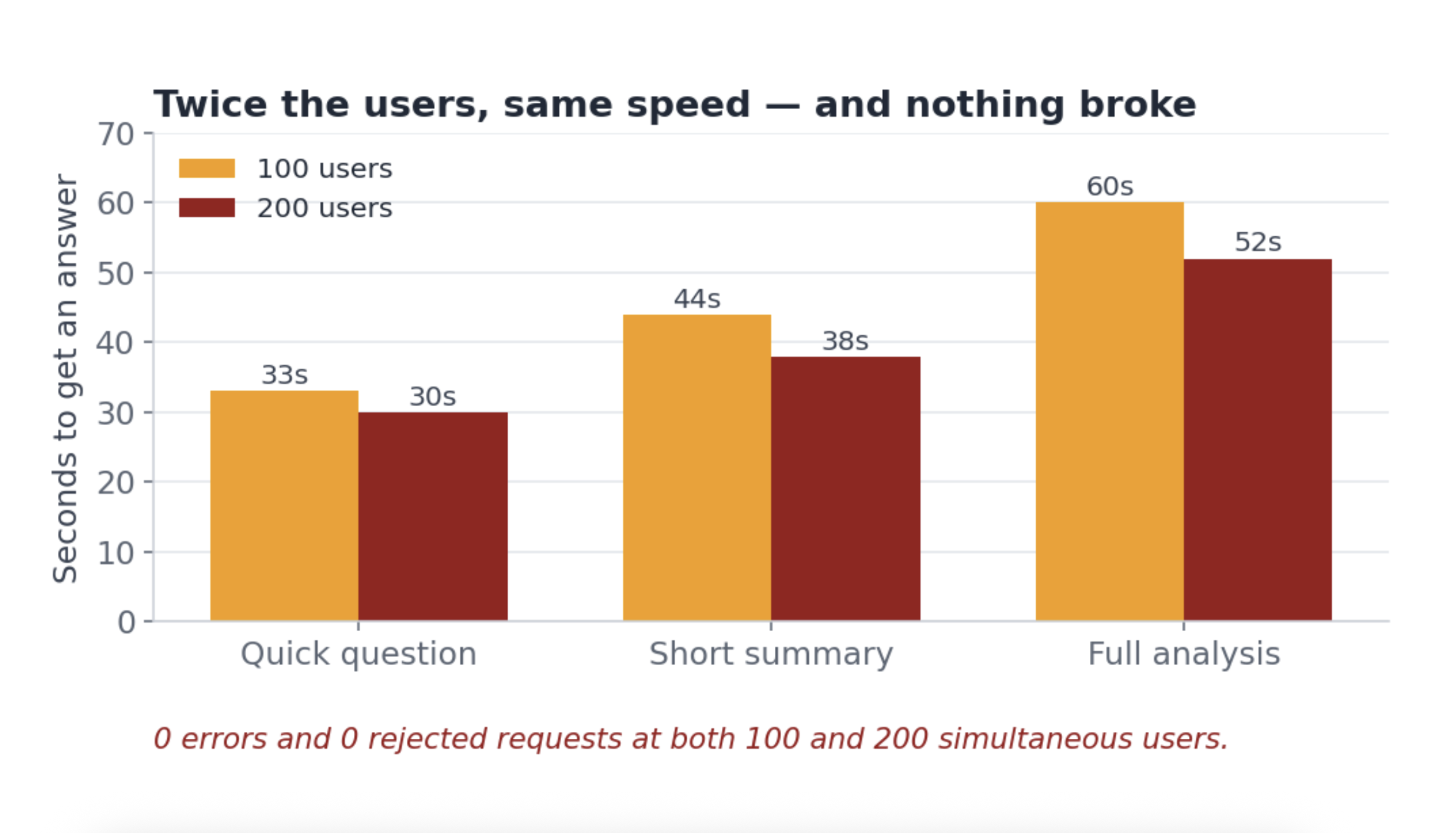
Nothing broke. No errors, no "try again later." Double the users and the total output doubled too. Honestly, I was impressed — Snowflake didn't flinch at 200.
But it was slow the whole way: about thirty seconds for a quick question, a full minute for a deep one, whether 100 people were asking or 200.
And that's for reading one transcript.
Now picture a real question, "summarize every competitor mentioned across my accounts," that has to read a hundred transcripts, asked by a hundred people at once. That's ten thousand analyses demanded on the spot.
At the speeds I measured, the folks at the back of that line are waiting tens of minutes, not seconds. (Rough estimate, I didn't run that exact test, but the throughput math is the throughput math.)
And to even reach 200, I had to stand up eight separate compute clusters and babysit them by hand, because a single one only handles a few dozen people at a time. Eight clusters, all running, all billing, for the length of the test.
So — does Rippit get to exist?
Here's what I walked away believing.
The raw capability is real. Snowflake and Cortex shrugged off 200 people without blinking, and I still love it.
But "it didn't crash" is a low bar for something people are supposed to enjoy using.
The distance between one person asking one question on one transcript and an AI product is almost invisible, right up until you're at scale. Then it’s the whole thing.
Keeping answers fast when everyone shows up at once.
Keeping the bill from quietly compounding.
Building an entire orchestration layer to spread the work across all that compute.
Reading 100% of the data instead of a convenient sample, without it taking six hours.
None of that is the model. The model is the easy part.
Everything around it — the tools, the environment, the engineering — is the actual job.
And yea: turns out Rippit gets to exist. I’ll keep stress-testing.
Too many blogs optimize for SEO or Chatbots versus serving the reader. We are prioritizing interesting content and to do this, here is our commitment to quality: Zero articles will be written by AI but AI will serve as an editing tool for the content.
The blogs will only be written by me, Vasu Prathipati, Co-Founder and CEO of Rippit, or Harrison Hunter, Co-Founder and CTO of Rippit
Future authors will be added but need to meet internal criteria of having insightful and specific thoughts, and are in the weeds of the product or with customers.

Vasu Prathipati
CEO and Co-Founder of Rippit


We tried to rebuild Rippit inside Snowflake to see if Cortex could do it alone. It didn't crash at 200 users — but "it didn't crash" is a low bar.
I really enjoy using Snowflake. I'm in it constantly. It's where our data lives, and most days it just quietly does what I need it to do.
I run finance and operations at Rippit. Part of what we do is conversation intelligence. Point us at your sales and support calls and we turn them into answers.
And Snowflake has a built-in AI service, Cortex, sitting right next to all that conversation data.
Which raises an obvious, slightly terrifying question:
Could you just… do this yourself, in Snowflake, without Rippit?
I genuinely wanted to know. Part curiosity, part self-preservation: if Snowflake can already do this on its own, Rippit's in real trouble.
So I tried to build Rippit in Snowflake, or at least the core of it, and push it until something broke.
The dream version is simple. Someone types a plain-English question — how are customers talking about us this month? which deals are slipping, and why? — and the system calls an LLM against the actual transcripts, on the fly, and hands back an answer.
All inside Snowflake. No extra infrastructure, no data leaving the building.
But before any of that, before Cortex reads a single word, I had to get the conversations into a shape so that the LLM could even analyze them.
Our conversations don't live in one tidy place. Sales calls come from Gong, support chats from Intercom. Both sync into Snowflake through Fivetran, but they land raw. And raw is a mess.
A Gong call isn't a transcript; it's hundreds of rows, one per spoken sentence, scattered across tables with speaker IDs and timestamps.
Intercom is the same idea in a different shape: each conversation is a pile of message "parts," wrapped in HTML, tagged by whether an agent, a customer, or a bot wrote them.
So before I could analyze anything, I had to do real data modeling.
That's a stack of dbt models and a daily pipeline standing between raw data and the very first question. None of it is hard, exactly, but it's hours of work and design decisions that I had to make. The LLM can't read what I hadn’t cleaned yet.
With the data finally in one clean, queryable place, I wired it up and started turning the dial: one user, then ten, then a hundred, then two hundred all asking at once.
I tracked how fast it answered, what it cost, and what fell over.
A few things surprised me.
When it felt slow, my first instinct was the lazy one: throw more hardware at it.
I 4x’d the compute. It only got 8% faster.
Here's why. The AI doesn't actually run on the computer you're paying to scale up. It runs on a separate, shared service behind the platform. Your compute just takes the order and carries the plate. The kitchen is somewhere else, and it cooks at its own pace.
A fancier waiter doesn't make the kitchen cook faster.
One answer is cheap. Reading a single transcript to answer a question costs about four cents on a premium model. Nobody's going to notice four cents.
But the questions worth asking don't read one transcript. They read all of them.
"Give me a competitive rundown across last quarter's calls" means actually reading last quarter's calls. Two hundred and fifty of them run about $11 and fifty minutes.
And it runs again, from scratch, every time someone tweaks the question or the data refreshes.
A premium model does give you a better answer: sharper, better at holding a complicated instruction. You just pay for that quality every time, across every conversation, and nothing warns you when you've wandered onto the expensive path.
We're used to AI replying in a second or two. That holds for one short question. It stops holding the moment you ask it to read a lot.
Twelve seconds per conversation. Fine on its own. But 250 conversations is nearly an hour.
The time grows in a straight line with the volume. There's no setting that makes "read everything" fast.
This was the real test I cared about. Picture a sales team on a Monday morning: dozens of reps all opening the tool and asking about their own accounts at the same time.
So I built up to it: a hundred simultaneous users, then two hundred.
Nothing broke. No errors, no "try again later." Double the users and the total output doubled too. Honestly, I was impressed — Snowflake didn't flinch at 200.
But it was slow the whole way: about thirty seconds for a quick question, a full minute for a deep one, whether 100 people were asking or 200.
And that's for reading one transcript.
Now picture a real question, "summarize every competitor mentioned across my accounts," that has to read a hundred transcripts, asked by a hundred people at once. That's ten thousand analyses demanded on the spot.
At the speeds I measured, the folks at the back of that line are waiting tens of minutes, not seconds. (Rough estimate, I didn't run that exact test, but the throughput math is the throughput math.)
And to even reach 200, I had to stand up eight separate compute clusters and babysit them by hand, because a single one only handles a few dozen people at a time. Eight clusters, all running, all billing, for the length of the test.
So — does Rippit get to exist?
Here's what I walked away believing.
The raw capability is real. Snowflake and Cortex shrugged off 200 people without blinking, and I still love it.
But "it didn't crash" is a low bar for something people are supposed to enjoy using.
The distance between one person asking one question on one transcript and an AI product is almost invisible, right up until you're at scale. Then it’s the whole thing.
Keeping answers fast when everyone shows up at once.
Keeping the bill from quietly compounding.
Building an entire orchestration layer to spread the work across all that compute.
Reading 100% of the data instead of a convenient sample, without it taking six hours.
None of that is the model. The model is the easy part.
Everything around it — the tools, the environment, the engineering — is the actual job.
And yea: turns out Rippit gets to exist. I’ll keep stress-testing.

The most valuable customer insight isn't common themes, it's the rare exceptions you almost miss.
Common customer questions in Rippit are:
- What are themes in my customer calls?
- What are common issues in last week’s customer support conversations?
I’ll tell you a real story — Rippit is going all in on this one product strategy. More details are coming soon, but in hindsight, we could have gone all in back in February. I lost three months.
How? A customer emailed me with a feature request that was this brilliant idea. I missed it.
It was a niche insight, not a common one.
If you want to find common themes, follow them up with the niche insights within those common themes.
The highest-value thing insights can give you is helping you see the future — it’s more valuable than insights to fix the current state.

Sampling gives you an answer. It doesn't give you the right answer — and that's the difference between Claude + Snowflake and Claude + Rippit.
Connect Claude to Snowflake and ask, "What are the top three reasons customers are churning?"
You'll get a confident answer that’s, on its face, incredibly compelling, with beautiful graphs and formatting.
But read the fine print. For example, Claude may say, the average transcript is ~34K characters. If I pulled the whole April/May window into context, that's ~340M chars — totally infeasible to read directly. So I need a sampling strategy.
Why 50? Why key word search? Why the first comment?
Why not 100% of all 10,000 conversations?
It's not the model. It's the tools.
The model is the brain, the tools are the arms and legs.
Claude and Rippit share the same brain.
So does Claude connected to any data source - Snowflake, a helpdesk, a call recorder, a chat platform, a CRM.
What's different is how Rippit can orchestrate the brain.
Claude writes SQL and Snowflake runs the query. Rows come back - including raw transcripts.
Claude has to load and read the transcripts into its context window and reason over them at query time.
That's the bottleneck.
A transcript could be 2,000 - 10,000 tokens, maybe more. Reading 50,000 of them to answer one question is both technically possible and economically insane.
Claude or any LLM cannot actually load 100% of the transcripts into its context window - so the LLM has to sample the transcripts someway.
The model summarizes the sample and reports back. It takes shortcuts because it has to.
Again - it will give you what seems to be an amazing answer, that may look totally defensible - but when you dig into what Claude actually did - it reveals all the shortcuts it took.
Different tool, same shape.
Connect Claude to Zendesk. Connect it to Gong. Connect it to Intercom, Salesforce Service Cloud, Front, Dialpad, Slack, Teams, your in-product chats, your agent-to-agent messages. Pick any conversation source.
Zendesk and Gong aren’t data platforms like Snowflake where they can handle 100% analysis on the fly for you so Claude has to sample from those sources and fit what it can in the context window which is a tiny percent of the total conversation volume.
Snowflake has the ability to enrich 100% of conversations but it is not designed for this so it’s too slow to be feasible - and requires more complex internal building.
Every conversation that lands in Rippit gets processed once, at ingestion. Topics. Intents. Sentiment. Escalations. Outcomes. Themes. Entities.
We’ve determined a number of data points that the most people will need and pre-enrich the conversations based on what we’ve learned over the past 10 years.
However, we also give customers the ability to build customized pre-enrichment prompts. Given every business is unique - the conversations each one is having is unique - therefore you should have the ability to customize what insights you want out of your data.
You define the questions you actually care about - "did the customer mention a competitor by name," "did the agent quote pricing," "was a regulatory term invoked," "did this conversation contain a renewal objection," “what was our customers’ thoughts on X new product” — and we run those against every single conversation at ingestion.
A custom question becomes a custom dimension. Asked once, answered across 100% of the corpus.
Those become structured dimensions and measures that Rippit can leverage when someone asks a question - this means each question is cheaper and faster.
This is why Rippit is better than the "Claude + warehouse" setup. The generic setup gives you raw text and asks the model to figure out your business at query time, every time, over a sample. Rippit lets you encode your business once and run it over everything.
The per-conversation model cost was paid once, asynchronously, at ingestion. Not on every analytical pass.
If you do take the time to build LLM pipelines, in Snowflake for example, you’ll find the cost wildly different from what it would cost in Rippit. We’re just passing through the cost that the model providers charge us - 1:1, whereas Snowflake marks up these tokens and recognizes that markup as revenue. Therefore, your LLM token costs are always 10-25% higher than using Rippit - when you get hooked and want to get more and more insight out of your data - that 10-25% turns into a much higher annual cost.
Pre-enrichment only covers some set of use cases customer ask about. You also need to do -on-the-fly enrichment
When you ask Rippit some questions, the model will need to read the raw transcripts to figure out the answer.
Rippit will run query time question-specific LLM calls over every conversation that has been selected for this analysis.
Pre-enrichment gives you a better baseline than what exists in your CRM or Phone System and on-the-fly enrichment is what gives you depth and 100% question coverage.
This is the part that should bother you most.
When the model samples 50 conversations and tells you the top three reasons customers are churning, it isn't lying. It found patterns. The patterns are real in those 50 conversations.
But it’s not verifiably accurate.
It's anecdotal evidence confidently articulated as analytics.
An LLM with a confident voice and three bullet points feels like a research report. It isn't. It's the equivalent of asking a consultant to talk to a couple customers at random and come back with a strategy memo. The summary will sound smart. The conclusions might even be directionally correct. They also might be completely wrong, and you have no way to know which.
You're going to take this answer into a board meeting. Or a roadmap review. Or a renewal conversation. Decisions get made on it. And the underlying evidence base is fifty conversations out of fifty thousand, picked by a heuristic nobody audited.
Here’s just three examples of where the anecdote-vs-statistics gap actually bites:
Rare events. If 2% of conversations contain a churn signal, a 50-conversation sample catches one of them, maybe. You'll never see the pattern. Compliance violations, executive escalations, regulatory disclosures - exactly the things you can't afford to miss, exactly the things sampling guarantees you'll miss.
Trend detection. Comparing two periods requires comparable coverage. Sample 50 last quarter and 50 this quarter, and the noise swamps any signal smaller than 20 points. With 100%, a 2-point shift in resolution rate is real.
Segmented analysis. "What are enterprise customers saying about pricing?" needs volume inside the segment. Sample globally and filter, and you've got three conversations from your top tier. Sample inside the segment, and you had to know the segment mattered before you sampled — which means you've already lost the ability to ask unanticipated questions.
Nothing comes for free. 100% coverage costs more. We’re not talking about how much we charge but literally costs more in AI tokens.
But you get the answer you can trust and make better decisions with.
Claude + Snowflake is a brain reaching for a tool that doesn't understand conversations.
Claude + Rippit is a brain reaching for a tool that already does.
Same model. Different tools. Different answers.

Prompt:
Can you use snowflake to tell me how customers are talking about Rippit and how that's changed over the last month or two?
Claude states that it has to sample and is just trying to determine the best approach
So the windows look like:
Average transcript is ~34K characters. If I pulled the whole April/May window into context, that's ~37M chars — totally infeasible to read directly. So I need a sampling strategy.
Where I'd actually start. Cheap signals first to find which calls are even worth opening, then read only those. Roughly:
Step 1: Scope the windows and drop unattributable calls. April-May 2026 = 1,099 calls, but ~250 of those have no ACCOUNT_ID (internal syncs, recordings that never got matched to a Salesforce account). Drop them — you can't talk about "customers" without knowing which customer. That leaves 852 attributed calls.
Step 2: Pick a role lens. CSM calls are where existing customers talk about the product. SDR/AE calls are pitch motion — different signal, separate analysis. For "what are customers saying about Rippit," restrict to CSM + Head of CS. That's 508 calls in Apr-May.
Step 3: Lexical filters to find candidate calls. Cheap and noisy, but better than random. The big lesson: most sentiment keywords are useless. "Love"/"great"/"amazing" matched 92% of all calls — they're filler. The keywords that do discriminate are concrete: product/brand mentions, named competitors, integration names (Gladly, Kustomer, Zendesk), specific surfaces (auto-QA, coaching, calibration, screen capture).
Step 4: Stratified one-call-per-account sampling. A naive random sample over-weights chatty accounts (Mindbody had 8 product-mention calls in 2 months). Take the most recent call per account so each customer voice gets weighted once.
Step 5: Snippet extraction, not full transcripts. Pull ±400 chars around the first brand mention. ~900 chars per call × 50 calls = 45K chars total — fits in one context window for thematic coding.
Step 6: Track keyword rates month-over-month. Raw counts are misleading because call volumes swing 30%+ month-over-month. Normalize as percent of CSM calls.
What the methodology misses: (in Claude’s own words)
Realistic conclusion: the lexical approach gets you the integration health questions (which CRM/help desk is the friction) and the vocabulary tracking questions (rebrand, named competitors) cheaply. It can't replace enrichment for sentiment, defect taxonomy, or churn-driver attribution - those genuinely need the LLM pass.
.png)
Surveys are the past, AI is the future — but neither Qualtrics nor Medallia is still led by the founder who could navigate the shift.
Surveys are the past. AI is the future — the #1 problem is neither Qualtics or Medallia is led by their founders anymore to navigate this change.
Ryan Smith started Qualtrics but now runs the Utah Jazz. Medallia is onto its 3rd or 4th CEO. Both are owned by private equity, so product innovation is behind them, as the goal of private equity is to squeeze profits.
It’s not like Marc Benioff, the founder of Salesforce, who is leading the company through this change.
Kudos to the founders of Qualtrics and Medallia. They did an incredible job pioneering a new cultural mindset around Experience Management.
I just don’t think their setup will thrive over the next decade — but if the founders come back, I will change my mind.
They won’t come back, though.

Conversation data is its own category. The platform that owns it is the Conversation Data Platform.

In-product human-to-human chats.
Customer conversations.
Agent-to-Agent conversations.
Employee-to-Agent conversations.
More conversations recorded.
Synthetic text datasets.
The way Splunk owned system logs.
The way CrowdStrike owned security logs.
There will be an application that owns conversation logs.
We call that a Conversation Data Platform.

Productivity is the wrong frame. 10x comes from judgement — and judgement is what AI improves most.

The 10x engineer isn't more productive because they squeeze more output in the same time as the 1x engineer. The 10x engineer is more creative and a better problem solver. The person has better judgement.
This is true for every person, in any role.
This is what AI will help people do the most.
AI can improve judgement by giving a person new insights they didn't have before. AI can improve judgement by helping you run experiments and prototypes faster.
Using Rippit is one way to improve judgement — you can get instant insights into a dataset that wasn't possible to analyze before.
Be curious and discover secrets with AI to improve judgement.
Don't focus on incremental improvements. Seek 10x.

The primary user of software tools is changing. Pre-2026 it was humans — post-2026, it's AI agents.
In my prior post, I talked about the Model versus Tools. The next interesting point around tools is who is going to be the primary user of them.
Pre-2026, the primary users of these tools were humans. Post-2026, it will be AI Agents.
Let’s say a human currently goes through 10 steps to achieve a goal. AI will eat away at each of those steps so that a human only has to do 8 steps, then 5 steps, and so forth — with the holy grail being 100% automation.
This is far more complicated than it sounds, but it gives you a sense of where products are pushing.
A key part is connecting a tool to as many different AI agents as possible.
Tactically, Rippit has tools to analyze conversation data. We use our own “brain” to leverage the tools, but we also want to make those tools available to other AI agents in other products. For example, Claude Code or Cursor should be able to use our tools to get customer insights for building features, and Figma, Replit, or Lovable should leverage customer insights to better design user experiences or marketing assets.

Traditional SaaS was built for humans. AI demands infrastructure — and most SaaS companies aren't built for it.
There has been infrastructure as SaaS for two decades. Think AWS, Snowflake, Datadog, Heroku, Databricks, Confluent, Stripe, Twilio, Crowdstrike, and more. These tools were built for engineers, extremely fast performance, or very large-scale datasets.
There are also SaaS applications. Think Salesforce, Hubspot, ServiceNow, Workday, Okta, and more. These tools were built for non-engineers.
Some of the above SaaS applications have evolved into infrastructure and AI won’t affect their role in the future as much — for instance, Salesforce is more like Snowflake than it is like Monday.com.
AI is commoditizing, neutering, and sometimes killing thinner SaaS applications that are more workflow than infrastructure.
What AI is not doing is killing software. Software is going to explode in value because of AI — if you turn your SaaS application into infrastructure.
The CEO of Intercom just did this last week when they released the Fin API. ElevenLabs is “SaaS as infrastructure,” whereas Decagon and Sierra are SaaS.
Hence, AI will force winning SaaS companies into infrastructure.
How SaaS as infrastructure will be different from traditional SaaS
SaaS apps are built with the expectation that a human is the primary user. SaaS as Infrastructure is built for an AI primary user.
When AI is the primary user, there are two implications:
How SaaS as Infrastructure will be different from infrastructure as SaaS:
Infrastructure as SaaS is built for technical folks. SaaS as infrastructure will be built for non-technical folks, and AI is a critical enabler to give non-engineers the superpowers of engineers.
I think Replit and Claude Code are two of the best examples of this type of company today. A non-technical user can execute a wide range of large and small tasks. They have built tools, frameworks, and infrastructure where AI is the primary user of “clicking buttons” and the human is expressing intent.
If you’re unclear on what I mean by tools, frameworks, and infrastructure, I talk about it more in It’s not the Model, it’s the Tools + Environment. You can also ask Claude Chat or Claude Code, “what tools do you have at your disposal?”, and it will give you a list. But it’s the tools, frameworks, and infrastructure that make the human user receive a fast output they can trust.
At Rippit, we’ve been preparing for this future since 2023. We didn’t know it would play out exactly like this, but we knew right when ChatGPT came out that our original product was going to get massively commoditized, and we needed to chase harder technical problems.
A little bit of foresight and a little bit of luck creates the Rippit opportunity.
Note: This concept is still being refined, but it is a directional set of statements. Please share ideas to push the thinking and refine the logic.
.png)
Stop reminiscing and start the ascent. The goal is simple: ensure tomorrow is always better than today.

Pick things that compound over time.
Wake up looking forward to the present.
Talk about ideas and projects of the future.
Reminisce less. The good old days are ahead of you, not behind you.
What ages like wine?
To each their own.
One hack is to have extremely low expectations to start.
The other hack is to reset your mindset today — no matter your age — and start over.
There's no better time to start the ascent than today.
This applies to companies too — is tomorrow potentially better than today?
Just Rip It.
Where conversations become
insights
actionable data
business intelligence
enterprise visibility
insights
