Mike Nucci
?? min read
Load Testing Conversation Analysis in Snowflake
We tried to rebuild Rippit inside Snowflake to see if Cortex could do it alone. It didn't crash at 200 users — but "it didn't crash" is a low bar.
BLOG


.png)
We tried to rebuild Rippit inside Snowflake to see if Cortex could do it alone. It didn't crash at 200 users — but "it didn't crash" is a low bar.
I really enjoy using Snowflake. I'm in it constantly. It's where our data lives, and most days it just quietly does what I need it to do.
I run finance and operations at Rippit. Part of what we do is conversation intelligence. Point us at your sales and support calls and we turn them into answers.
And Snowflake has a built-in AI service, Cortex, sitting right next to all that conversation data.
Which raises an obvious, slightly terrifying question:
Could you just… do this yourself, in Snowflake, without Rippit?
I genuinely wanted to know. Part curiosity, part self-preservation: if Snowflake can already do this on its own, Rippit's in real trouble.
So I tried to build Rippit in Snowflake, or at least the core of it, and push it until something broke.
The dream version is simple. Someone types a plain-English question — how are customers talking about us this month? which deals are slipping, and why? — and the system calls an LLM against the actual transcripts, on the fly, and hands back an answer.
All inside Snowflake. No extra infrastructure, no data leaving the building.
But before any of that, before Cortex reads a single word, I had to get the conversations into a shape so that the LLM could even analyze them.
Our conversations don't live in one tidy place. Sales calls come from Gong, support chats from Intercom. Both sync into Snowflake through Fivetran, but they land raw. And raw is a mess.
A Gong call isn't a transcript; it's hundreds of rows, one per spoken sentence, scattered across tables with speaker IDs and timestamps.
Intercom is the same idea in a different shape: each conversation is a pile of message "parts," wrapped in HTML, tagged by whether an agent, a customer, or a bot wrote them.
So before I could analyze anything, I had to do real data modeling.
That's a stack of dbt models and a daily pipeline standing between raw data and the very first question. None of it is hard, exactly, but it's hours of work and design decisions that I had to make. The LLM can't read what I hadn’t cleaned yet.
With the data finally in one clean, queryable place, I wired it up and started turning the dial: one user, then ten, then a hundred, then two hundred all asking at once.
I tracked how fast it answered, what it cost, and what fell over.
A few things surprised me.
When it felt slow, my first instinct was the lazy one: throw more hardware at it.
I 4x’d the compute. It only got 8% faster.
Here's why. The AI doesn't actually run on the computer you're paying to scale up. It runs on a separate, shared service behind the platform. Your compute just takes the order and carries the plate. The kitchen is somewhere else, and it cooks at its own pace.
A fancier waiter doesn't make the kitchen cook faster.
One answer is cheap. Reading a single transcript to answer a question costs about four cents on a premium model. Nobody's going to notice four cents.
But the questions worth asking don't read one transcript. They read all of them.
"Give me a competitive rundown across last quarter's calls" means actually reading last quarter's calls. Two hundred and fifty of them run about $11 and fifty minutes.
And it runs again, from scratch, every time someone tweaks the question or the data refreshes.
A premium model does give you a better answer: sharper, better at holding a complicated instruction. You just pay for that quality every time, across every conversation, and nothing warns you when you've wandered onto the expensive path.
We're used to AI replying in a second or two. That holds for one short question. It stops holding the moment you ask it to read a lot.
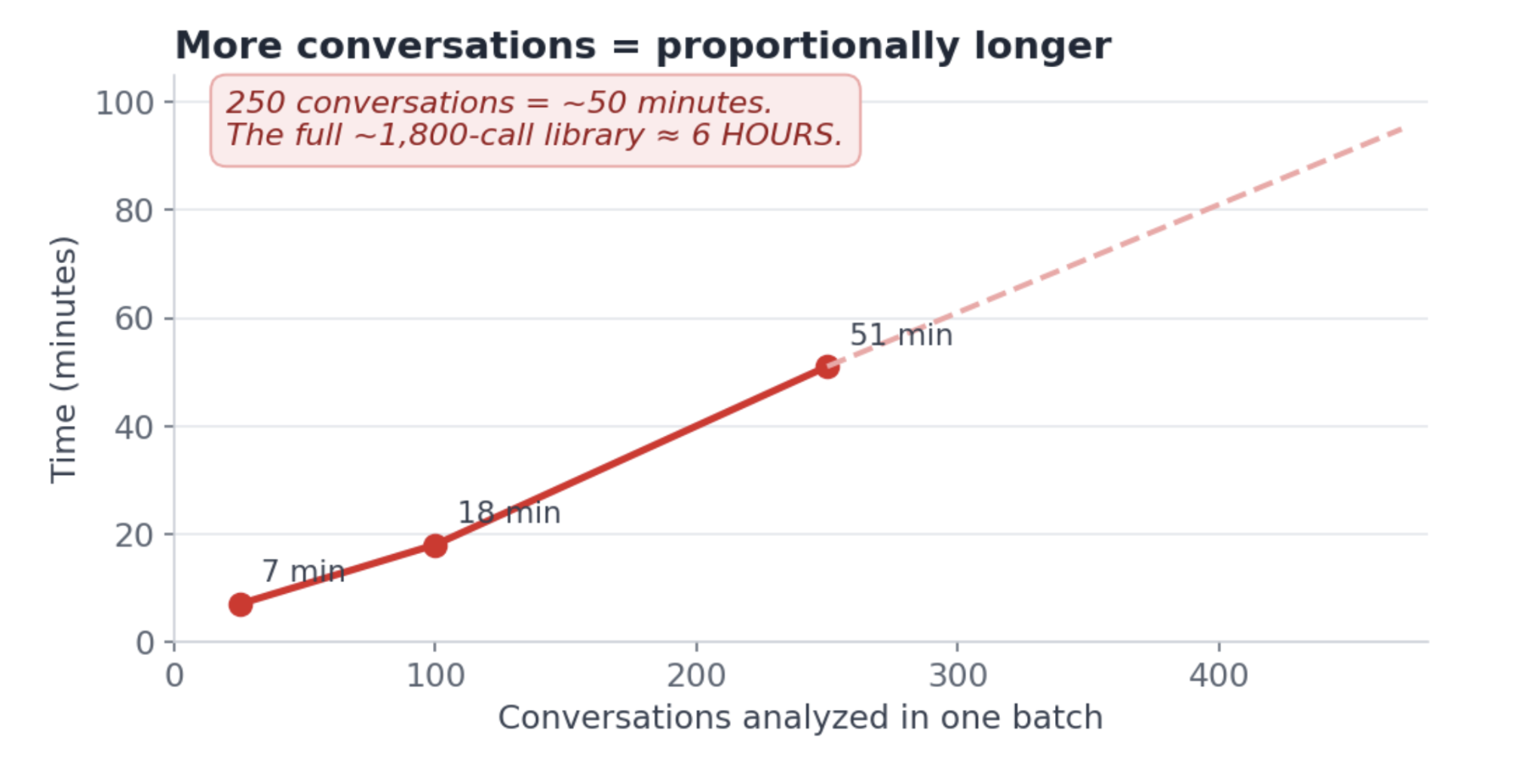
Twelve seconds per conversation. Fine on its own. But 250 conversations is nearly an hour.
The time grows in a straight line with the volume. There's no setting that makes "read everything" fast.
This was the real test I cared about. Picture a sales team on a Monday morning: dozens of reps all opening the tool and asking about their own accounts at the same time.
So I built up to it: a hundred simultaneous users, then two hundred.
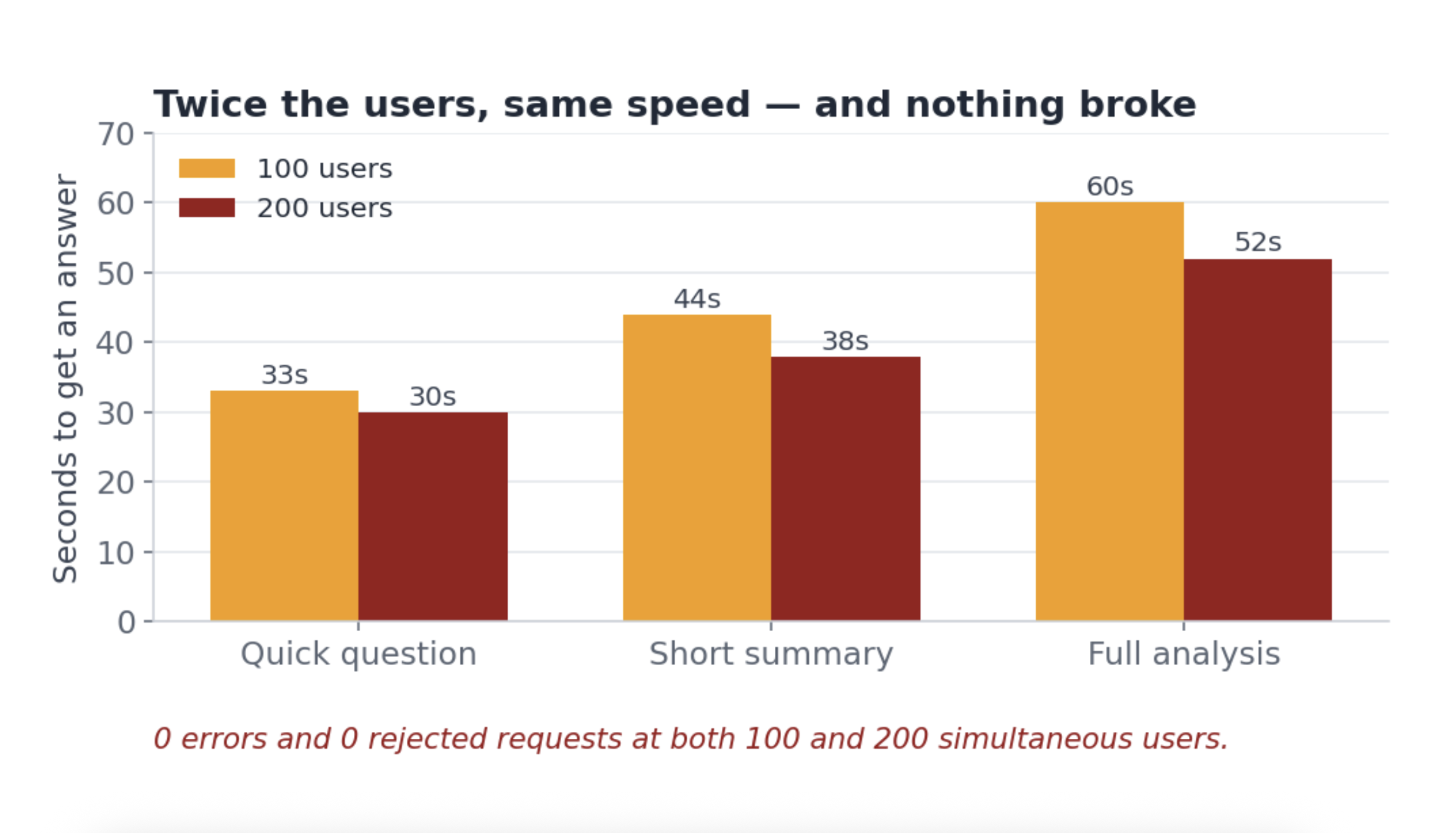
Nothing broke. No errors, no "try again later." Double the users and the total output doubled too. Honestly, I was impressed — Snowflake didn't flinch at 200.
But it was slow the whole way: about thirty seconds for a quick question, a full minute for a deep one, whether 100 people were asking or 200.
And that's for reading one transcript.
Now picture a real question, "summarize every competitor mentioned across my accounts," that has to read a hundred transcripts, asked by a hundred people at once. That's ten thousand analyses demanded on the spot.
At the speeds I measured, the folks at the back of that line are waiting tens of minutes, not seconds. (Rough estimate, I didn't run that exact test, but the throughput math is the throughput math.)
And to even reach 200, I had to stand up eight separate compute clusters and babysit them by hand, because a single one only handles a few dozen people at a time. Eight clusters, all running, all billing, for the length of the test.
So — does Rippit get to exist?
Here's what I walked away believing.
The raw capability is real. Snowflake and Cortex shrugged off 200 people without blinking, and I still love it.
But "it didn't crash" is a low bar for something people are supposed to enjoy using.
The distance between one person asking one question on one transcript and an AI product is almost invisible, right up until you're at scale. Then it’s the whole thing.
Keeping answers fast when everyone shows up at once.
Keeping the bill from quietly compounding.
Building an entire orchestration layer to spread the work across all that compute.
Reading 100% of the data instead of a convenient sample, without it taking six hours.
None of that is the model. The model is the easy part.
Everything around it — the tools, the environment, the engineering — is the actual job.
And yea: turns out Rippit gets to exist. I’ll keep stress-testing.
Too many blogs optimize for SEO or Chatbots versus serving the reader. We are prioritizing interesting content and to do this, here is our commitment to quality: Zero articles will be written by AI but AI will serve as an editing tool for the content.
The blogs will only be written by me, Vasu Prathipati, Co-Founder and CEO of Rippit, or Harrison Hunter, Co-Founder and CTO of Rippit
Future authors will be added but need to meet internal criteria of having insightful and specific thoughts, and are in the weeds of the product or with customers.

Vasu Prathipati
CEO and Co-Founder of Rippit



Traditional SaaS companies are workflow tools, but AI demands data apps. This shift is an extinction event for 99% of engineering cultures—and a forced evolution for founders who think they can stay non-technical.
Traditional business application software from 2000-2022 (e.g. software sold into HR, Sales, Marketing, etc.) has been primarily workflow automation tools — Salesforce started with SFA (Salesforce Automation), ServiceNow started with IT Workflow Automation, and Workday is HR workflow automation.
The core value proposition was coordinating large groups of people around a process.
When you wanted to do complex data analysis — crunch lots of numbers, combine data from different data sources, etc. — you would push that data into a data warehouse (Teradata in the 2000s, later replaced by Snowflake) and layer it with a BI solution (like Tableau or, more recently, Sigma/Looker).
SaaS apps that lived in the world of Security and Infrastructure were more likely data/infra apps from the beginning — companies like Rubrik, Crowdstrike, and Datadog fit this mold.
The type of engineers and cultures you attract to build workflow apps versus data apps is materially different.
AI requires a higher percentage of SaaS apps to become data apps.
99% of apps will die in this process because they have to build a fundamentally different engineering culture. Only 1% will survive.
Rippit realized this three years ago and embarked on this journey — partly through our instinct of how SaaS needed to transform, and partly through a little bit of luck.
This also transforms my role, and I’m going through my own journey of survival. As a non-engineer, being the founder of a workflow app is significantly less technical and more S&M-oriented than being the founder of a data app.
My Monday morning meeting used to be the Go-To-Market kickoff and now it’s the Engineering kickoff. I’m working very hard to become as effective as I can at lower levels of product decisions — my ceiling here directly affects Rippit’s ceiling.

Why does Claude Code outperform standard chat? LLM tooling and environments—not just the model—are the keys to great AI outputs.
When you use Claude Code, you see the same model (ex. Opus 4.6) is used across Claude Code, Claude Cowork, and Claude Chat. Then why does it perform differently? The tools and environment.
Think of the model as the brain and the tools as the arms, hands, legs, and feet.
Claude Code has many coding-specific tools.
What you need for your task will require specific tools, environments, and optimizations too.
Designing the best tools and environments is going to be the name of the game.
For example, if you want to build an analytics system, you connect Claude to Snowflake. In that case, Snowflake is the tool. Snowflake is the hard part of the problem and 99% of companies don’t have the engineers to build products as technically difficult as Snowflake.
This has become more obvious since the code behind Claude was leaked the other week and people studied it - but it’s not obvious to the regular person blown away by Claude Code and “Vibe Coding”. When you experience a crazy, mind-blowing output, it's hard to separate the 'AI' from the tools and systems doing the mission-critical heavy lifting.
The world of Tool Design is going to go through a lot of trial, iteration, and realization — we have our differentiated POV but the playbook is being written.

Our product vision is unique and high-potential, but it’s the hardest thing we have ever set out to build.
Our product vision is unique and high-potential, but it’s the hardest thing we have ever set out to build.
In our All Hands on Tuesday, I expressed to the team:
What we’re trying to build is the hardest thing we’ve ever tried to build.
We have a 60% chance of building our vision at a high enough quality.
But if we do — it is going to be an amazing product.
Oh, and the world is moving so fast that we have less than 12 months to prove a couple of key technical milestones.
That’s how it should be — it is meant to feel scary and exciting at the same time.

Watch out for AI companies that make money the more you spend on AI.
Watch out for AI companies that make money the more you spend on AI.
They are charging some hard-to-tell upcharge on AI, which they package up as AI credits.
When a company charges this way, they are not incentivized to build cost-efficient AI because the more you spend on AI, the more money they make.
For example, they might use more expensive AI models when they could use less-expensive ones.
They could have the AI run for 15 seconds longer, in what they call “Thinking Mode,” and make more money in those 15 seconds.
When the AI makes a mistake, as long as it’s not so often that you cancel the contract, they are less motivated to fix the error rate because every mistake actually earns them money.
In a world where AI is becoming like electricity, and everyone has access to the same AI models, we believe software companies should not upcharge for AI directly.
This ensures the company’s incentives are aligned with customers' best interest.
I am not sure how most Conversation Analytics solutions charge because pricing is not transparent on the website.
However, if a Conversation Analytics solution does not have usage-based pricing for AI, that is a different red flag. What this suggests is you will not have the required flexibility to do all the AI analysis you might want.
When a solution is not charging explicitly for AI, they need to make sure that if you pay them $10, you don't consume more than $10 worth of AI. They probably need to make sure you don’t consume more than $4. So, they will throttle AI usage and impose constraints to ensure costs stay below that threshold — which can result in lower quality intelligence.
We think it’s critical that customers can pay for AI on a usage basis, but to avoid the first trap, they should charge for AI at cost or as a pass-through.
I wrote this post before Clay announced their pricing change, and I originally intended to use them as a poster child for the pricing trap they found themselves in. However, kudos to the Clay team for changing their pricing model the right way. Read about it as another example of what I’m articulating above and similar to our approach:

Rippit analyzed 20+ Gong calls in one shot, instantly connecting the dots in customer prep to nail high-stakes panel sessions.
I was moderating two panels at our customer conference in San Francisco the other month — one with Checkr and one with SpotOn.
The day before, I was finalizing my questions and deck, and I realized my notes from my prep calls with the customers had some logical gaps.
I went into Rippit, filtered our Gong table to all Checkr calls, and started asking questions using AskRippit. I did the same with SpotOn.
Afterward, I asked the marketing team a simple question: “Where else could I analyze 50 Gong calls in one shot as easily as Rippit?”
If you downloaded the 20 calls out of Gong 1 by 1 and then uploaded it into Claude, you have a chance, but for reasons I’ll share later — you lose accuracy.
That led me to think about how I prepared my deck. I used Gamma instead of Google Slides. I tried Google Slides first, but the AI wasn’t good enough — so I was willing to pay for Gamma. For me, in my role, I’ll pay for whatever helps me deliver the best presentation.
The same goes for conversation analysis for my use cases — I’d rather pay for Rippit than try to hack it in ChatGPT or Claude.

Great AI products shouldn't require a services team to set up—if you can’t learn it yourself in 10 minutes, the product is failing you.
Every software company is building AI into their product. As we embark on the Rippit journey, something we have spent a lot of time thinking about over the last 2-3 years is: what are the attributes of great products?
In the technology industry, there has been a lot of talk about Forward-Deployed Engineers (FDE). These are people who work with the customers to customize the product to a customer's needs.
What they are primarily doing is building prompts for LLMs on behalf of customers.
This sounds like a great deal for the customer, and it often leads to customers giving their business to the company that offers more services and help.
Our pre-Rippit experience suggests that this is a death trap for the company and customer within 24-36 months.
When a software company is small, early customers get the best employees as Forward-Deployed Engineers, and because the company is desperate for early customers, they also under-charge for the human resources they provide. Both of these things have to change for the software company to succeed over time.
The average customer loses the best FDE involved in their success. The average customer has to pay more for people resources.
Because the company has committed to a strategy where humans fill in product gaps, the product gets harder and harder to use over time.
What ends up happening is only the most important customers have good customer experiences.
I’ve lived this. I don’t think you can offer the FDE model to deliver a high quality customer experience unless the customer is paying $500,000/Year (±$250,000). It’s very hard to hire enough high-quality Forward-Deployed Engineers to match your growing customer count.
This is why I think Great AI Products have to be easy enough to use that a customer could learn them on their own. It is the most important criterion when judging a Great AI Product.
That’s why we’ve committed to this strategy at Rippit — we’re not where we want to be yet, but we are making progress.
This also seems to be the defining attribute of the best software products we use internally, like Figma, ChatGPT, Claude, Ramp, Cursor, Snowflake, AWS, and more.
We felt even higher conviction when we evaluated the alternatives for Voice of Customer software, Quality Assurance software, Experience Management software, and Conversation Intelligence software. All of them require FDEs — the signal was that they all had minimum price points of $25,000 to $50,000. That is way too much friction for many potential customers.
I’m not sure a single one lets you sign up for the product without talking to a human, which is often another signal of a complex product. The ones I researched were Qualtrics, Medallia, Enterpret, Chattermill, Unwrap, Loris, Level AI, Observe.AI, Cresta, MaestroQA, Balto, and unitQ.
I think Great AI Products have to be so easy to use that you can sign up and learn them yourself within 10 minutes.
Not everyone in the industry agrees with me — in fact, I think most won’t.
Some will argue it’s different for products selling to B2B or certain industries.
Some will argue that companies with FDEs will use the learnings from customers to build an easier product. The reality is it’s very hard to keep the plane flying just as fast while building an easier-to-use product — and it requires a different product culture. It requires a founder to potentially slow growth down and rearchitect everything, and only the exceptions have the courage to do that.
Everyone will admit that deploying AI in all situations will get easier over time — similar to how making a website got easier from the 1990s to 2020.
There might be an exception but I’m not letting the exception be the rule.
Lastly, similar to how it’s harder to write fewer words than many words to get a point across, it’s harder to make easy-to-use software than hard-to-use software. I think people who argue for complexity are often scared to step up to the engineering challenge.
Where conversations become
insights
actionable data
business intelligence
enterprise visibility
insights
