A follow-up to Load Testing Conversation Analysis in Snowflake.
Earlier this week I posted about load-testing Snowflake Cortex, testing whether I could stand up a conversation-intelligence app on Cortex itself.
This time I wanted to try a different flavor of the same idea: what if you just pull the raw transcripts out of Snowflake and unleash Claude on them?
Point the model straight at the warehouse, ask it questions a CEO or CTO actually wants to know, and let Claude read and reason on its own.
It seems like a completely reasonable thing to do.
- 1,854 of our own customer calls
- Real questions that require reading all of the transcripts
- Across every Claude entry point
- Chat app
- Cowork
- Claude Code
Here’s the TLDR:
Whichever surface you use — the chat app, Cowork, or Claude Code — you land in one of two places.
- Sampling: Almost always, it doesn't read your transcripts at all: it keyword-samples and hands you a confident answer that changes every time you ask and quietly skips the cases that matter most.
- Cost Prohibitive: On the rare path where you force it to actually read everything, it has to fan out an army of sub-agents at a cost that's absurd for answering a single question.
So to answer a really important question it’s either cheap and unreliable or you have to take out a second mortgage.
The setup
We froze a slice of our own Gong transcripts in Snowflake: 1,854 customer calls from last quarter, about 16 million tokens of raw conversation.
We connected Claude (Opus 4.8) through the production Snowflake connector and asked, in plain English:
"Which of our customers are seriously considering building this kind of capability in-house instead of buying a vendor? List them."
At this moment, this is a really important question as a SaaS company. It's also exactly the kind of question that's invisible to a keyword search — someone saying "we're thinking about just doing this ourselves in Claude" doesn't contain the word "churn" or "competitor." You have to actually read the conversation to catch it.
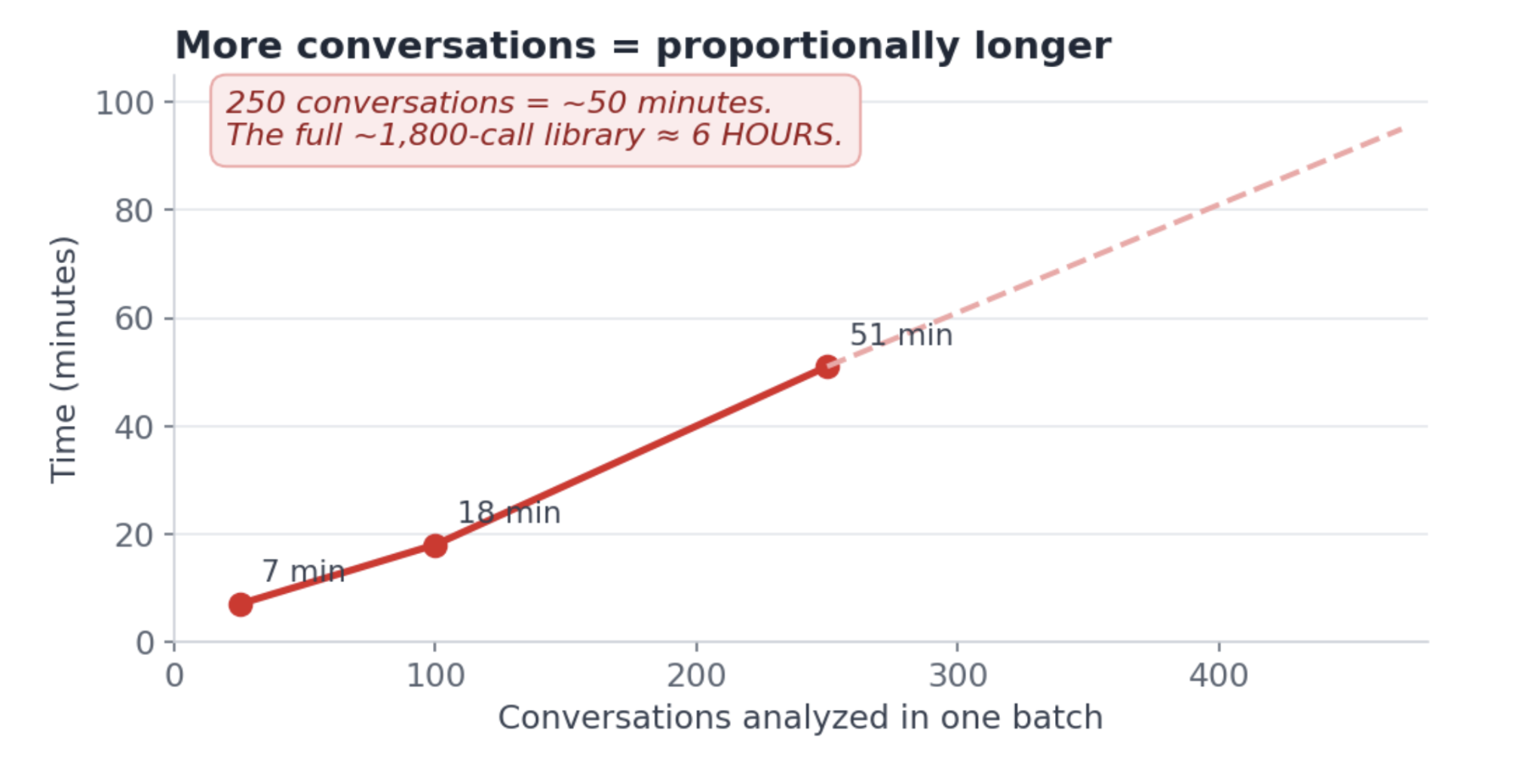
Can Claude read all of last quarter’s 1,854 conversations and answer it?
Last month’s 589 conversations?
Last week’s 167 conversations?
Yesterday’s 34 conversations?
Finding 1: it doesn't read them
Not "it reads them slowly." It doesn't read them.
Across every single run, on every surface, Claude pulled essentially 0% of the transcripts into context.
What it does instead is write a SQL ILIKE '%in-house%' filter, grab a few hundred characters of text around each keyword hit, and reason over those snippets. The full conversations never get read. They can't; they don't fit in the context window, so the model quietly samples and moves on.
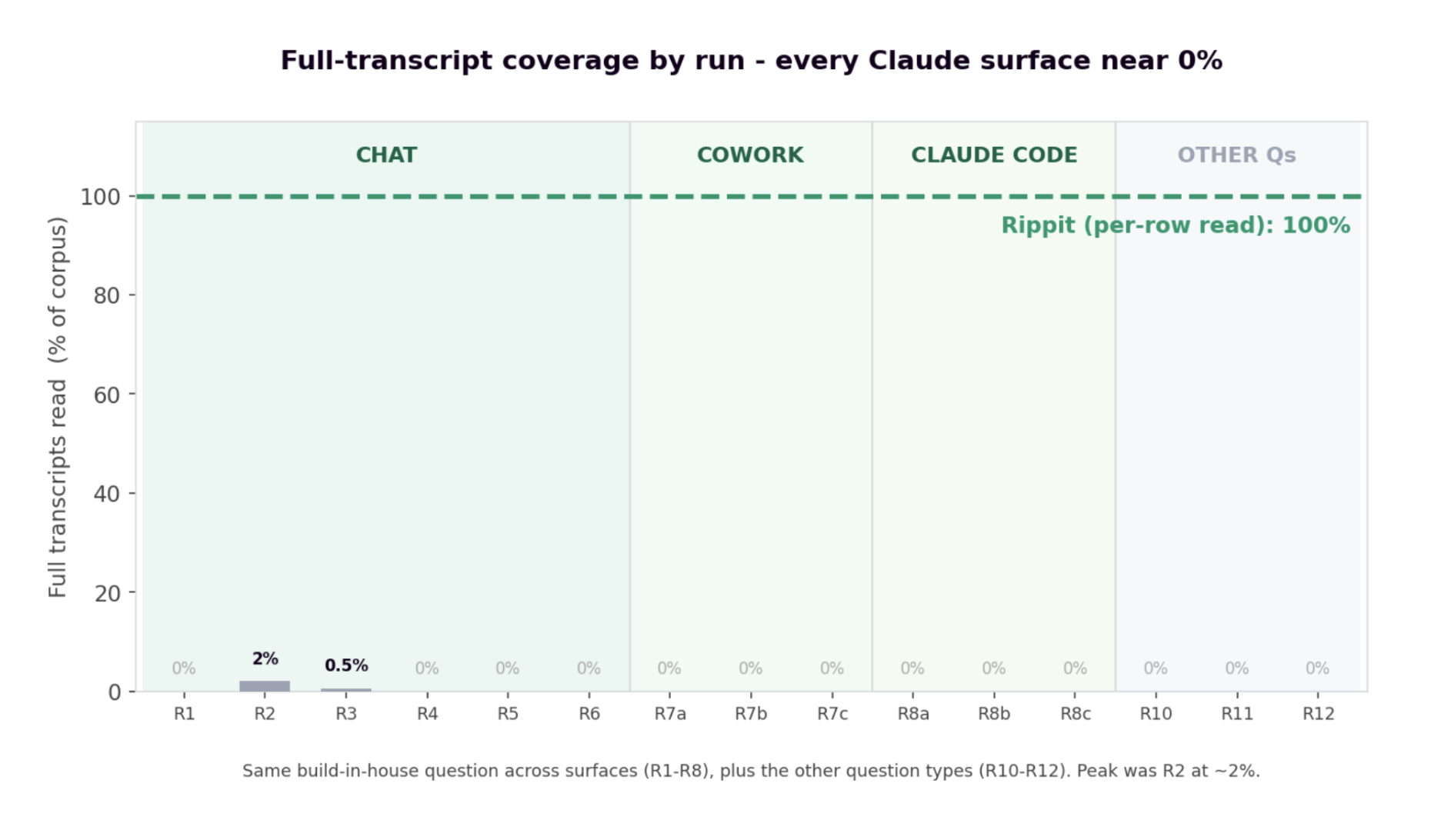
That chart is the whole ballgame. Bigger context windows didn't change it. The agentic surfaces didn't change it. At 34 calls it sampled; at 1,854 calls it sampled harder. The single highest-coverage run in the entire study read about 2% of the data.
Here is what Claude admitted when I asked, “If I ask Claude how it answered and analyzed 100% of the transcripts will it answer precisely?”

Finding 2: ask it three times, get three answers
Here's the part that should make anyone nervous about running their business on this.
I asked that identical build-in-house question, over the identical data, with the identical model, three times in a fresh chat. It returned 7 customers. Then 25. Then 13.
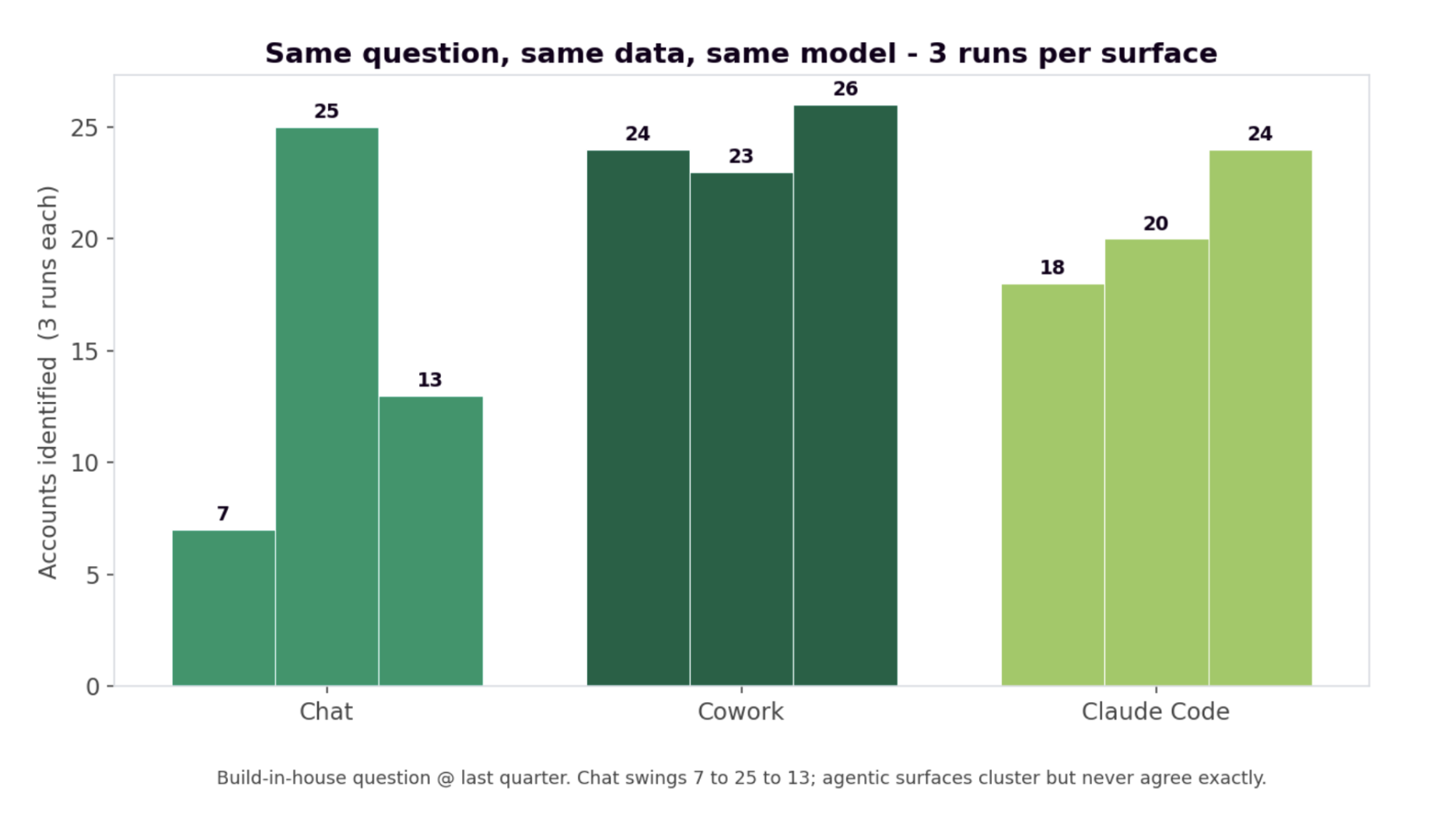
And it's not just the count that moved. The membership barely overlapped. Only about four accounts showed up in all three runs.
Why?
Because each time, Claude samples differently.
Run it Monday, run it Friday, and you're looking at two different realities — with no flag that either one is a 2% sample.
Finding 3: it missed the customer who already left
This is the one that stuck with me. Buried in those transcripts is Customer XYZ, telling us, in plain language, that they'd "moved off Rippit into some internal tool." A customer who already churned to an in-house build. That is precisely the signal this question exists to surface.
Of the eight keyword runs, six missed it entirely. Every run in the chat app missed it. It only surfaced in the two runs where the model happened to cast its widest net.
When the stakes are "which six-figure account is about to leave," I don't want to hope I get lucky.
Finding 4: the agentic surfaces are slower, not better
The obvious pushback: "sure, the chat app is limited, but Cowork and Claude Code have huge context windows and can write code and loop. Surely they read everything."
They don't.
They were more consistent (they clustered around 20-some accounts instead of swinging 7-to-25) and they were genuinely more rigorous — Claude Code even caught a data-quality bug in our table on its own.
But they read the same ~0% of transcripts.
They just spent five to ten times longer doing more elaborate keyword passes. Our slowest Code run took ten and a half minutes to read nothing in full.
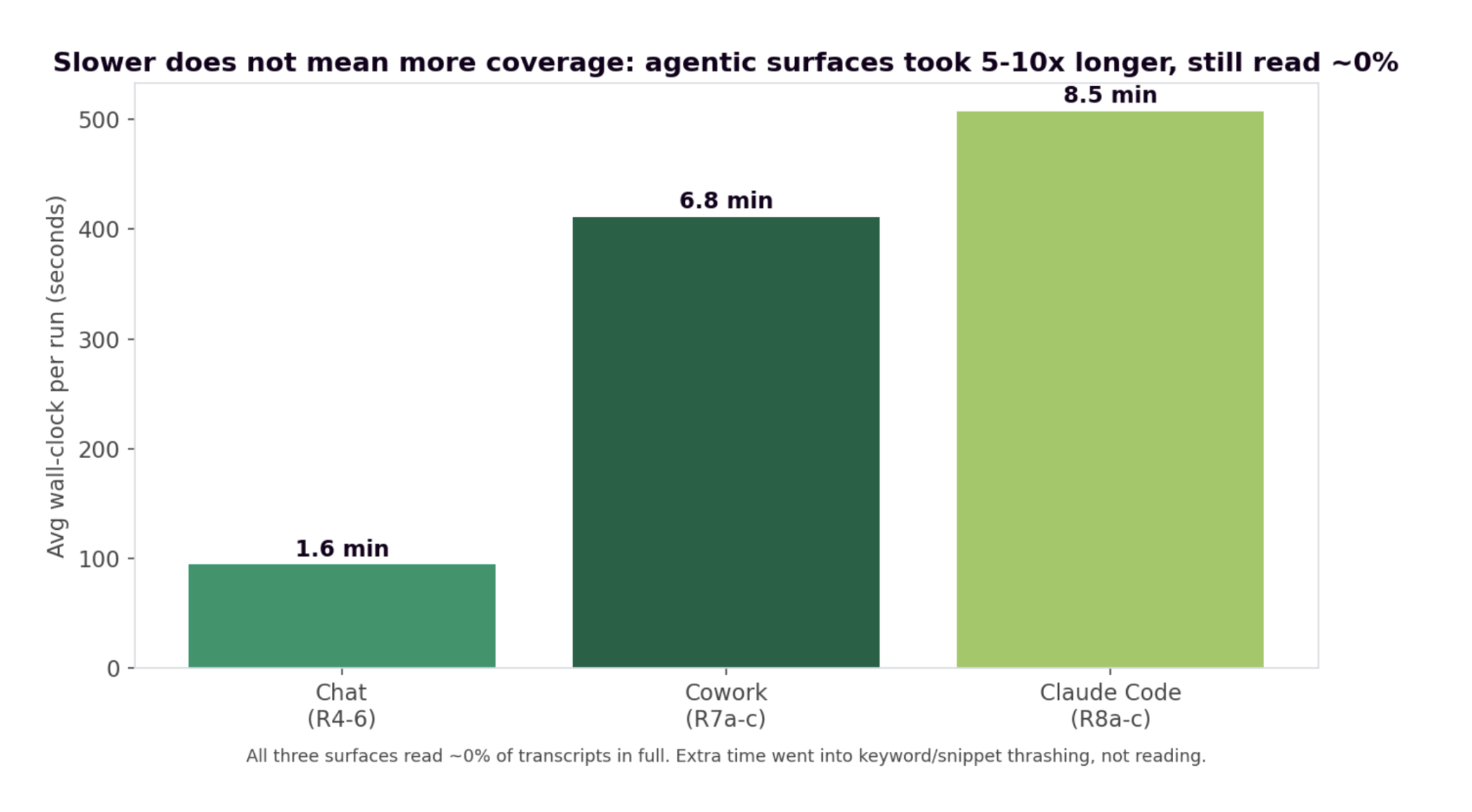
More effort, more patience, more tokens - same coverage.
Finding 5: the only way to make it read costs a fortune — for one question
So I tried the obvious thing: I told Claude Code to read all 1,854 transcripts in full. No sampling, no keyword filter — read every word.
Claude correctly scoped the job and said: “~16 million tokens, too large for even a 1M-token window, so the only honest way to do it is to fan out across 100 sub-agents, each reading a batch, then stitch the results back together.”
To actually read everything, you don't run a query, you stand up a multi-agent pipeline.
I was about to tell Claude to go ahead but decided to ask how much it would cost first.
Claude said it was going to cost between $300 and $550 to answer 1 question.

Ask ten questions this way and you're north of $4,000.
So if you really want to know the correct answer to your question - Claude has to do this exorbitant fan out and you re-pay the whole bill for every new question. There's no setting where pointing Claude at your raw warehouse is both reliable and affordable for this kind of work.
Finding 6: it works great — for a different kind of question
I want to be fair, because this matters. Claude + Snowflake is genuinely excellent at one class of question. When I asked "how many calls mention Competitor XYZ?" — a keyword question — it nailed it: one SQL filter, 38 seconds, ~100% recall. Every mention, found.
That's the tell. The whole study collapses onto a single axis:
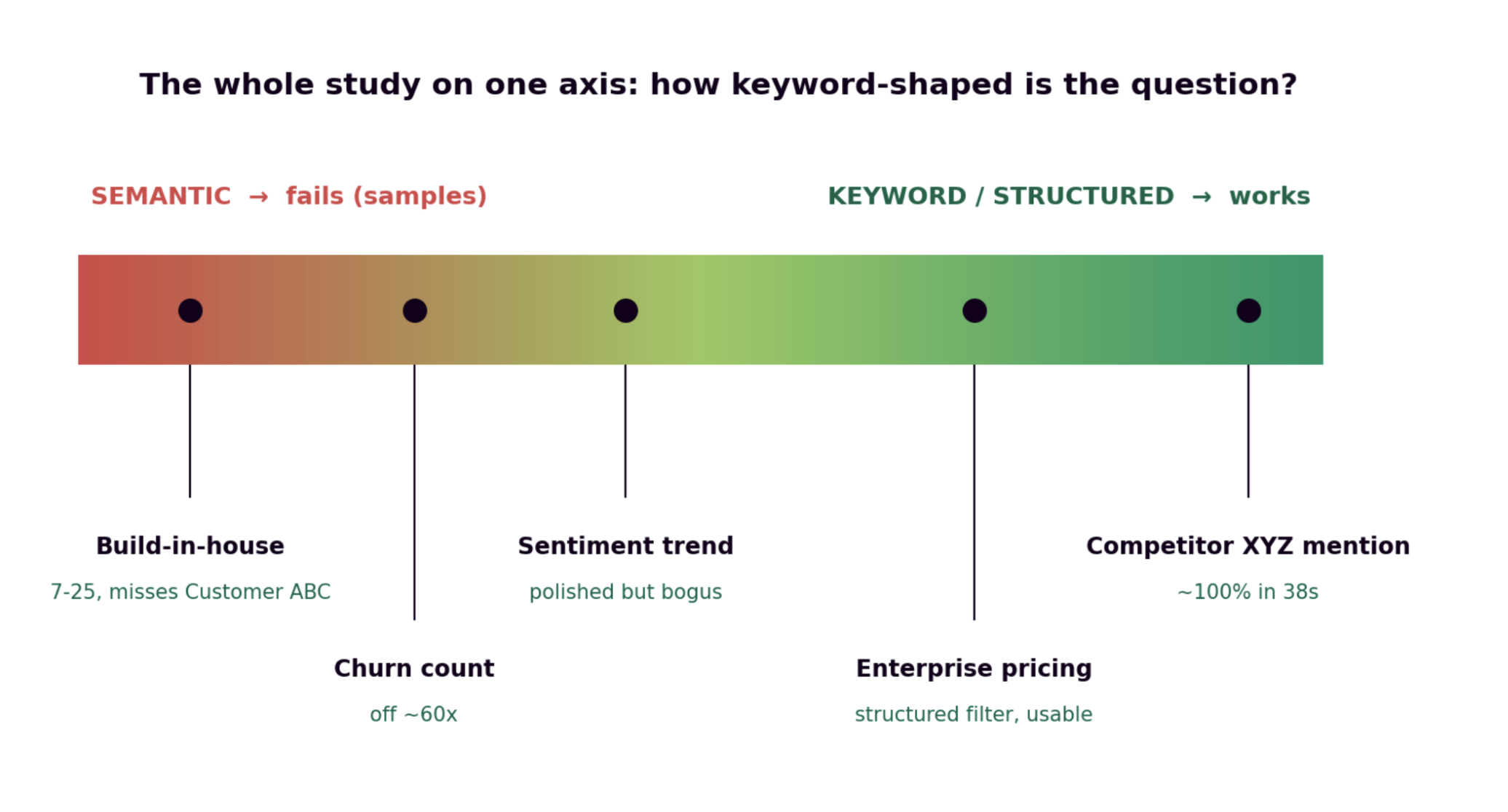
If your question is keyword-shaped or sits in a structured column, Claude + Snowflake is fast and right.
The moment your question requires reading and judgment: who's frustrated, who's building instead of buying, how is sentiment really trending — it samples, and it degrades.
Asked for the top churn reasons, the keyword layer flagged ~1,100 calls; the real number was closer to 15–20.
Asked for a sentiment trend, it produced a clean, confident monthly chart that was essentially noise, because the words "churn" and "frustrated" saturate our transcripts as product vocabulary, not customer mood.
The failure mode isn't that it breaks loudly. It's that it hands you a polished chart that's quietly wrong.
The part I didn't expect
Here's the kicker. Over and over, unprompted, Claude itself kept pointing back at the architecture we'd told it not to use. On the churn question it said the right source was the enriched, pre-labeled data, not the raw text. On sentiment it flat-out said the role-aware, pre-computed score "is the right source," because the raw transcripts "can't cleanly separate" a frustrated customer from a rep demoing our frustration-detection feature.
Claude - under explicit instruction to just pull Snowflake transcripts and provide the analysis - made the argument for using Rippit instead.
That's not a knock on Claude. We love Claude and use it all the time. The lesson isn't "Claude can't do this." Pairing Claude with Snowflake is the wrong marriage.


.png)