
.png)
I really enjoy using Snowflake. I'm in it constantly. It's where our data lives, and most days it just quietly does what I need it to do.
I run finance and operations at Rippit. Part of what we do is conversation intelligence. Point us at your sales and support calls and we turn them into answers.
And Snowflake has a built-in AI service, Cortex, sitting right next to all that conversation data.
Which raises an obvious, slightly terrifying question:
Could you just… do this yourself, in Snowflake, without Rippit?
I genuinely wanted to know. Part curiosity, part self-preservation: if Snowflake can already do this on its own, Rippit's in real trouble.
So I tried to build Rippit in Snowflake, or at least the core of it, and push it until something broke.
The experiment
The dream version is simple. Someone types a plain-English question — how are customers talking about us this month? which deals are slipping, and why? — and the system calls an LLM against the actual transcripts, on the fly, and hands back an answer.
All inside Snowflake. No extra infrastructure, no data leaving the building.
But before any of that, before Cortex reads a single word, I had to get the conversations into a shape so that the LLM could even analyze them.
Our conversations don't live in one tidy place. Sales calls come from Gong, support chats from Intercom. Both sync into Snowflake through Fivetran, but they land raw. And raw is a mess.
A Gong call isn't a transcript; it's hundreds of rows, one per spoken sentence, scattered across tables with speaker IDs and timestamps.
Intercom is the same idea in a different shape: each conversation is a pile of message "parts," wrapped in HTML, tagged by whether an agent, a customer, or a bot wrote them.
So before I could analyze anything, I had to do real data modeling.
- Stitch the sentence rows back into one ordered transcript per call.
- Label who's speaking, [agent] vs. [customer], so the model isn't guessing.
- Strip the HTML out of the Intercom threads.
- Force two completely different sources into one common shape: one row per conversation, one clean transcript field, and shared columns like account, date, and channel.
- And join all of it back to Salesforce, so a question like "which deals are slipping" even knows what a deal is.
That's a stack of dbt models and a daily pipeline standing between raw data and the very first question. None of it is hard, exactly, but it's hours of work and design decisions that I had to make. The LLM can't read what I hadn’t cleaned yet.
With the data finally in one clean, queryable place, I wired it up and started turning the dial: one user, then ten, then a hundred, then two hundred all asking at once.
I tracked how fast it answered, what it cost, and what fell over.
A few things surprised me.
Buying a bigger computer did almost nothing
When it felt slow, my first instinct was the lazy one: throw more hardware at it.
I 4x’d the compute. It only got 8% faster.
Here's why. The AI doesn't actually run on the computer you're paying to scale up. It runs on a separate, shared service behind the platform. Your compute just takes the order and carries the plate. The kitchen is somewhere else, and it cooks at its own pace.
A fancier waiter doesn't make the kitchen cook faster.
The good questions are the expensive ones
One answer is cheap. Reading a single transcript to answer a question costs about four cents on a premium model. Nobody's going to notice four cents.
But the questions worth asking don't read one transcript. They read all of them.
"Give me a competitive rundown across last quarter's calls" means actually reading last quarter's calls. Two hundred and fifty of them run about $11 and fifty minutes.
And it runs again, from scratch, every time someone tweaks the question or the data refreshes.
A premium model does give you a better answer: sharper, better at holding a complicated instruction. You just pay for that quality every time, across every conversation, and nothing warns you when you've wandered onto the expensive path.
It's a slow cooker, not a microwave
We're used to AI replying in a second or two. That holds for one short question. It stops holding the moment you ask it to read a lot.
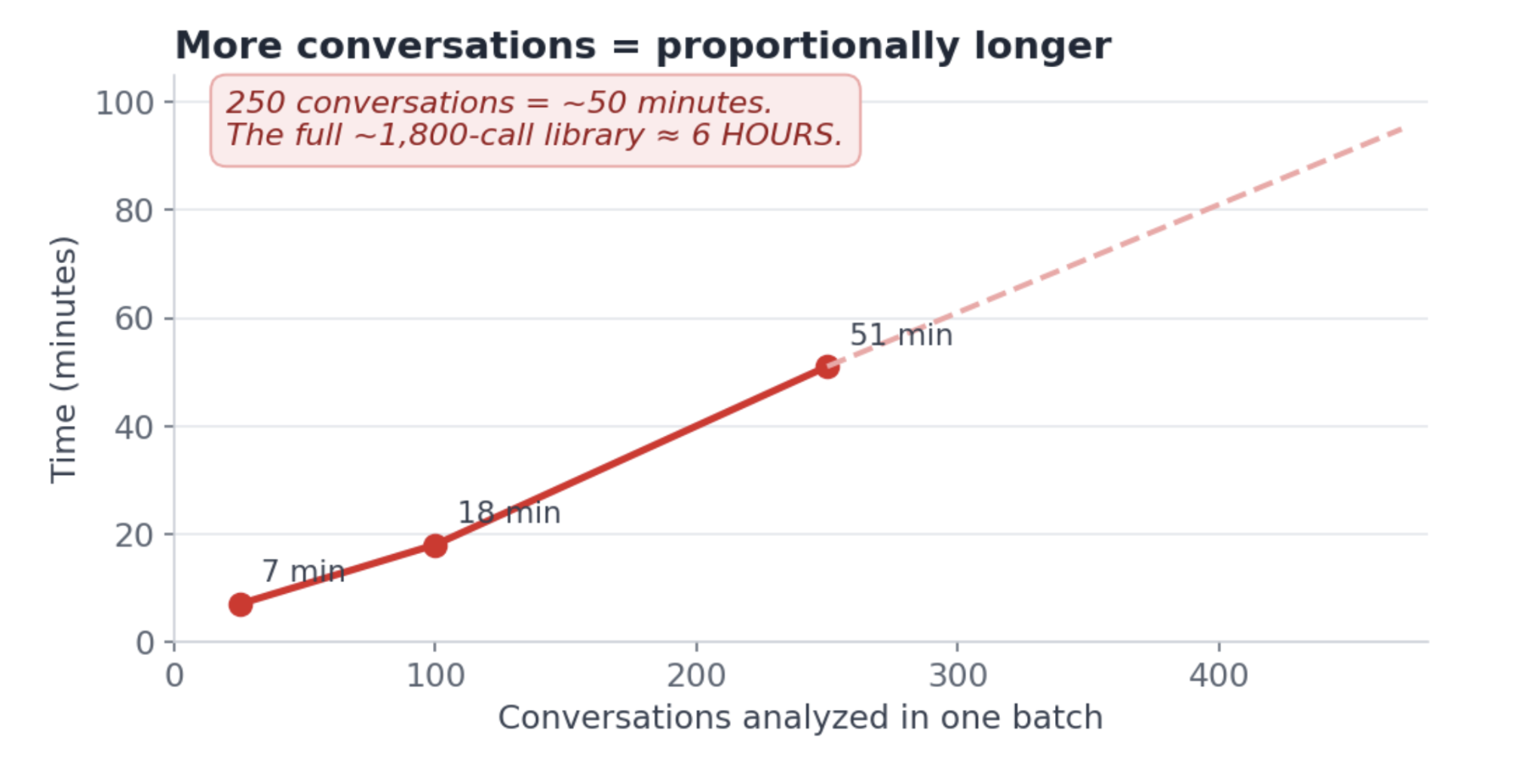
Twelve seconds per conversation. Fine on its own. But 250 conversations is nearly an hour.
The time grows in a straight line with the volume. There's no setting that makes "read everything" fast.
200 people at once? It didn't break. It was really slow.
This was the real test I cared about. Picture a sales team on a Monday morning: dozens of reps all opening the tool and asking about their own accounts at the same time.
So I built up to it: a hundred simultaneous users, then two hundred.
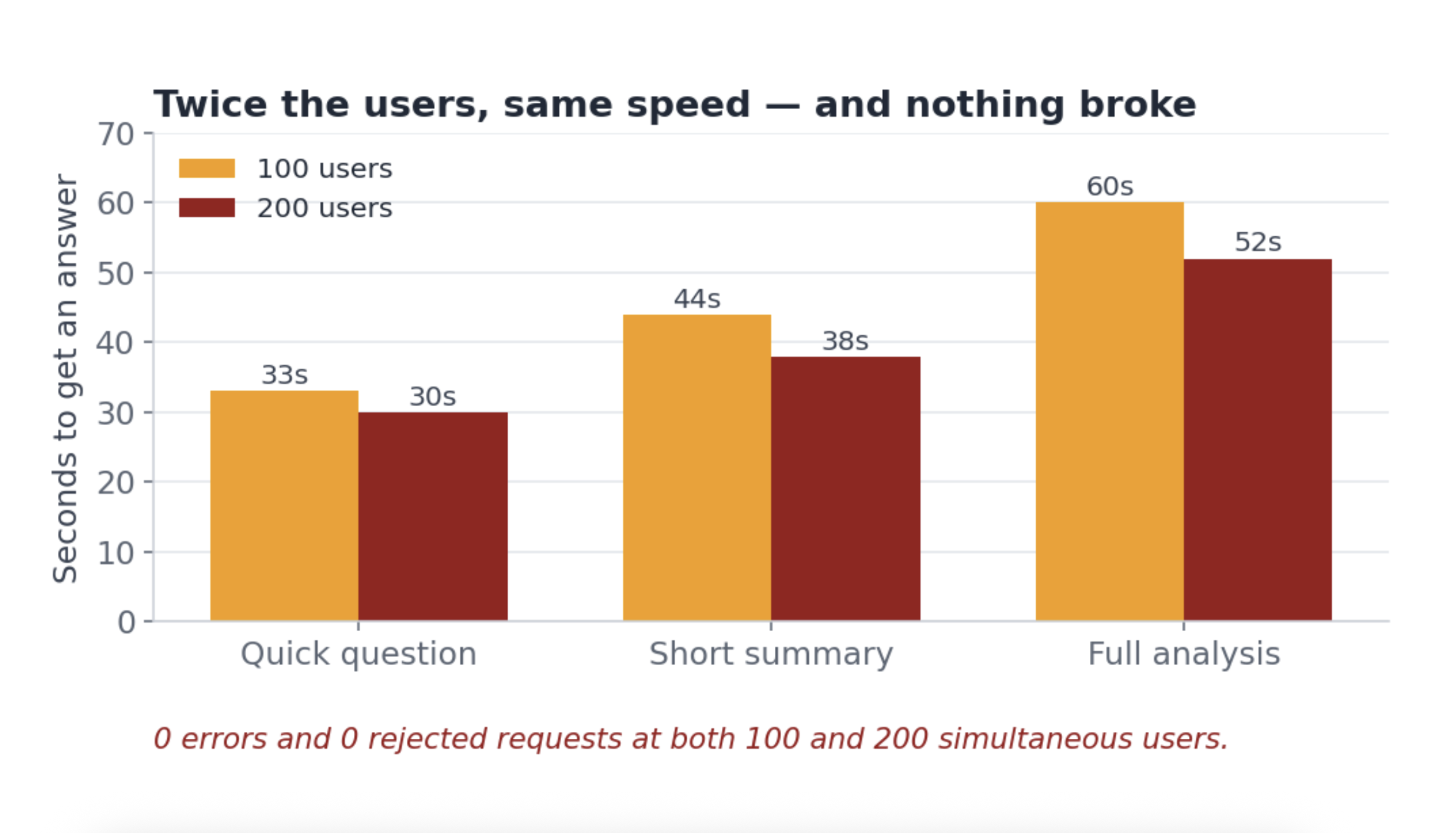
Nothing broke. No errors, no "try again later." Double the users and the total output doubled too. Honestly, I was impressed — Snowflake didn't flinch at 200.
But it was slow the whole way: about thirty seconds for a quick question, a full minute for a deep one, whether 100 people were asking or 200.
And that's for reading one transcript.
Now picture a real question, "summarize every competitor mentioned across my accounts," that has to read a hundred transcripts, asked by a hundred people at once. That's ten thousand analyses demanded on the spot.
At the speeds I measured, the folks at the back of that line are waiting tens of minutes, not seconds. (Rough estimate, I didn't run that exact test, but the throughput math is the throughput math.)
And to even reach 200, I had to stand up eight separate compute clusters and babysit them by hand, because a single one only handles a few dozen people at a time. Eight clusters, all running, all billing, for the length of the test.
It's not the LLM model. It's everything around it.
So — does Rippit get to exist?
Here's what I walked away believing.
The raw capability is real. Snowflake and Cortex shrugged off 200 people without blinking, and I still love it.
But "it didn't crash" is a low bar for something people are supposed to enjoy using.
The distance between one person asking one question on one transcript and an AI product is almost invisible, right up until you're at scale. Then it’s the whole thing.
Keeping answers fast when everyone shows up at once.
Keeping the bill from quietly compounding.
Building an entire orchestration layer to spread the work across all that compute.
Reading 100% of the data instead of a convenient sample, without it taking six hours.
None of that is the model. The model is the easy part.
Everything around it — the tools, the environment, the engineering — is the actual job.
And yea: turns out Rippit gets to exist. I’ll keep stress-testing.




